My research
My research focus is in developing artificial intelligent learning and control systems, with special emphasis on applications in energy systems (smart grids), biomedical engineering, and quantitative finance.
In spite of their differences in many ways, artificial intelligence (AI) and control theory have been tight to each other since they were first invented. In fact, the earlist concept of artificial intelligent control system can be traced back to Wiener’s Cybernetics in 1940s. It is also interesting to know that Bellman proposed his famous dynamic programming theory, which coined the mathematical fundation beind reinforcement learning, even four years before the Dartmouth workshop, also known as the founding event of AI. More recently, AI has also inspired tons of intelligent control techniques, such as neural network control and adaptive dynamic programming (ADP). My ultimate research goal is to build a unified theoretical framework to bridge the gap between AI and control theory. This interdisciplinary study will enhance our understanding of the relationship between AI and control theory, and eventually inspire numerous future works in these fields.
Dynamic Programming (DP)

Value iteration (VI) in continuous-time
Originated by Bellman in 1959, VI has been widely adopted to find optimal policies for different types of systems.
However, despite its popularity, VI is flawed as it is only applicable in discrete-time.
In this project, we developed a complete framework of continuous-time VI for general nonlinear optimal control problems.
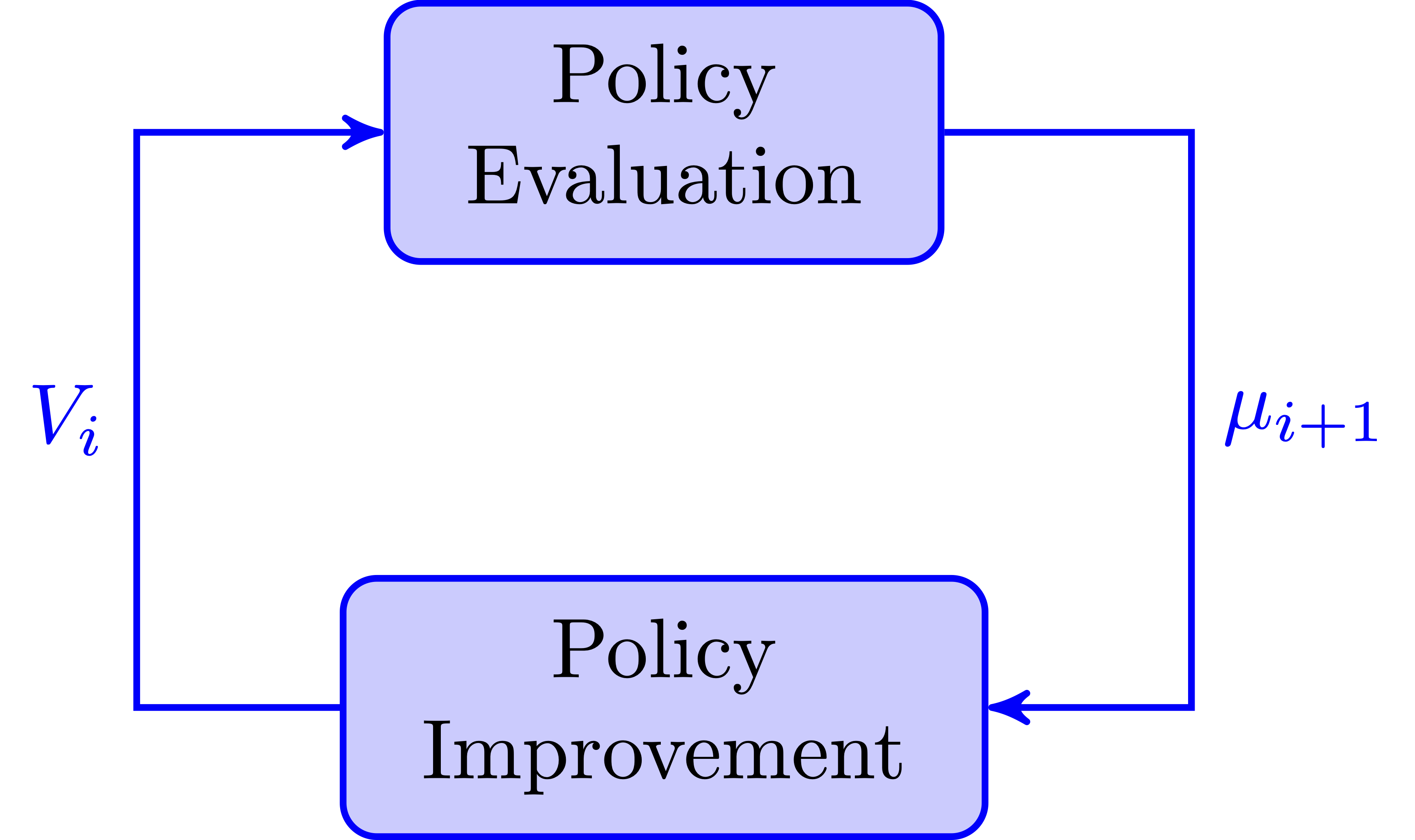
Policy iteration (PI) in continuous-time
Different from VI, PI starts from an admissible policy \(\mu_0\). Before the development of VI, PI was the dominant approach to solve continuous-time adaptive optimal control problems.
The first continuous-time PI was proposed by Kleinman in 1960s. The main advantage of PI is its simple formulation and quadratic convergence speed.
Reinforcement Learning (RL) and Adaptive DP (ADP)

The idea of RL, first introduced by Minsky in 1954, is to provide an understanding of activities such as the learning, memorizing, and thinking processes in human brain, and ultimately construct a system that can duplicate these “sentient”.
In this research work, we developed a new RL technique, under the name of ADP, for continuous learning environments.
ADP guarantees both stability and optimality of the controlled process.
Deep adaptive DP
The Cartpole model is a widely used benchmark in control engineering. Combing ADP with deep learning techniques, we built an AI to play the Cartpole game in OpenAI’s gym. Keras is used to build a deep neural network for approximating the unknown functions in the ADP algorithm.

Robust DP and robust ADP
Robust DP and robust ADP aim at strengthening DP and RL algorithms so that they are robust to the presence of disturbances and adversaries in the environment.
Different from existing robust optimizaton and robust learning frameworks, our methods are effective in dealing with both static and dynamic uncertainties.
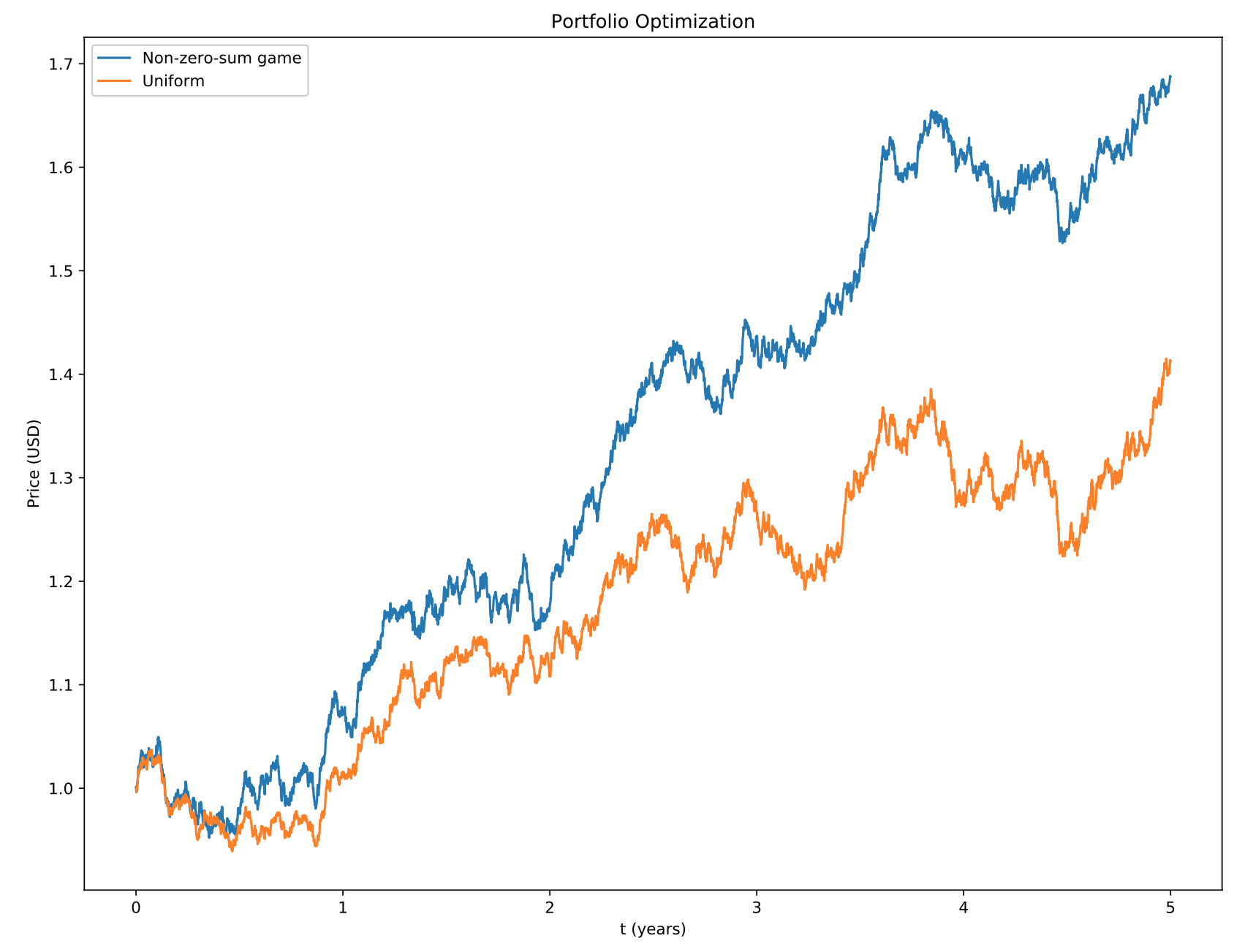
Robust DP in asset allocation
We used robust DP together with non-zero-sum game to build a learning-based dynamic asset allocation algorithm.